Abstract
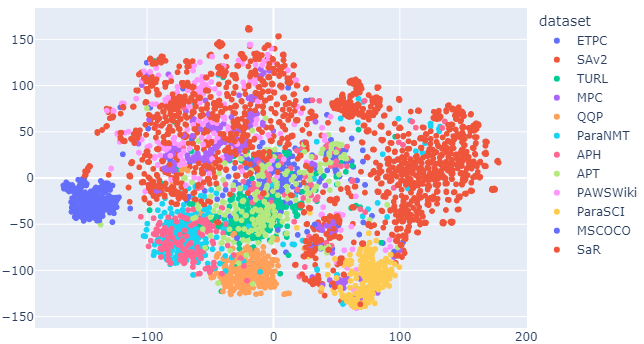
The growing prominence of large language models, such as GPT-4 and ChatGPT, has led to increased concerns over academic integrity due to the potential for machine-generated content and paraphrasing. Although studies have explored the detection of human- and machine-paraphrased content, the comparison between these types of content remains underexplored. In this paper, we conduct a comprehensive analysis of various datasets commonly employed for paraphrase detection tasks and evaluate an array of detection methods. Our findings highlight the strengths and limitations of different detection methods in terms of performance on individual datasets, revealing a lack of suitable machine-generated datasets that can be aligned with human expectations. Our main finding is that human-authored paraphrases exceed machine-generated ones in terms of difficulty, diversity, and similarity implying that automatically generated texts are not yet on par with human-level performance. Transformers emerged as the most effective method across datasets with TF-IDF excelling on semantically diverse corpora. Additionally, we identify four datasets as the most diverse and challenging for paraphrase detection.